Many organizations using the Ansible Automation Platform (AAP) still provision virtual machines manually and then run playbooks afterward. That process often involves waiting for infrastructure tickets, scheduling jobs, and completing lengthy configuration steps. In some cases, it can take hours or even days for a system to be ready for use.
Packer can communicate with both the cloud and the hypervisor, as well as a provisioner, changing the workflow to mint golden images. Deployments begin with a system that is ready in minutes, not days. Although it includes native Ansible support, Enterprise architects often point out problems right away: “You are bypassing all the governance we have built around AAP. No centralized logging, no RBAC, no audit trails, and no consistent execution environments.” For teams that rely on AAP for governance and standardized workflows, local Ansible runs create silos or force duplication. To address this, a custom Packer provisioner was built to integrate directly with the AAP API. Instead of running Ansible locally, Packer now calls job templates from AAP during image builds, enabling organizations to continue using their existing playbooks and environments while benefiting from the speed and repeatability of image factories.
With this approach, image builds run under the same governance as production workloads and benefit from centralized logging, RBAC, and consistent execution environments. Concerns about bypassing controls disappear since all automation stays inside AAP. The result is faster provisioning, reusable images, and an automation workflow that feels both modern and enterprise-ready.
Using the Provisioner
First the plugin will need to be added to the required plugins:
packer {
required_plugins {
ansible-aap = {
source = "github.com/rptcloud/ansible-aap"
version = "1.0.0"
}
}
}Then within the build spec, the provisioner can be configured to your AAP instance, assigned a job template ID, and all API orchestration occurs within the code. In a packer template, it would look something like:
build {
sources = ["source.amazon-ebs.example"]
provisioner "ansible-aap" {
tower_host = "https://aap.example.com"
access_token = vault("secret/data/aap", "access_token")
job_template_id = 11 # Job template to install docker on host
organization_id = 1
dynamic_inventory = true
extra_vars = {
Name = "packer-ansible-demo"
Environment = "production"
BuiltBy = "packer"
}
timeout = "15m"
poll_interval = "10s"
}
}amazon-ebs.example: output will be in this color.
==> amazon-ebs.example: Prevalidating any provided VPC information
==> amazon-ebs.example: Prevalidating AMI Name: packer-ansible-demo-20250820181254
...
==> amazon-ebs.example: Waiting for SSH to become available...
==> amazon-ebs.example: Connected to SSH!
==> amazon-ebs.example: Setting a 15m0s timeout for the next provisioner...
amazon-ebs.example: 🌐 Attempting to connect to AAP server: https://aap.example.com
amazon-ebs.example: 🔧 Initializing AAP client...
amazon-ebs.example: ✅ AAP client initialized successfully
amazon-ebs.example: 🎯 Creating inventory for target host: 54.146.55.206
amazon-ebs.example: 🗄️ Using organization ID: 1
amazon-ebs.example: ✅ Created inventory with ID: 75
amazon-ebs.example: ✅ Created SSH credential ID: 63
amazon-ebs.example: 🖥️ Adding host 54.146.55.206 to inventory
amazon-ebs.example: ✅ Added host ID: 66
amazon-ebs.example: 🚀 Launching job template ID 10 for target_host=54.146.55.206
amazon-ebs.example: ✅ Job launched https://aap.example.com/execution/jobs/playbook/142/output/. Waiting for completion...
amazon-ebs.example: ⏳ Polling job status...
amazon-ebs.example: 🎉 Job completed successfully!
amazon-ebs.example: Identity added: /runner/artifacts/142/ssh_key_data (packer-aap-key)
amazon-ebs.example:
amazon-ebs.example: PLAY [Install Docker] **********************************************************
amazon-ebs.example:
amazon-ebs.example: TASK [Gathering Facts] *********************************************************
amazon-ebs.example: [WARNING]: Platform linux on host 54.146.55.206 is using the discovered Python
amazon-ebs.example: interpreter at /usr/bin/python3.7, but future installation of another Python
amazon-ebs.example: interpreter could change the meaning of that path. See
amazon-ebs.example: https://docs.ansible.com/ansible-
amazon-ebs.example: core/2.16/reference_appendices/interpreter_discovery.html for more information.
amazon-ebs.example: ok: [54.146.55.206]
amazon-ebs.example:
amazon-ebs.example: TASK [Update package cache] ****************************************************
amazon-ebs.example: ok: [54.146.55.206]
amazon-ebs.example:
amazon-ebs.example: TASK [Install Docker] **********************************************************
amazon-ebs.example: changed: [54.146.55.206]
amazon-ebs.example:
amazon-ebs.example: TASK [Start and enable Docker service] *****************************************
amazon-ebs.example: changed: [54.146.55.206]
amazon-ebs.example:
amazon-ebs.example: TASK [Add ec2-user to docker group] ********************************************
amazon-ebs.example: changed: [54.146.55.206]
amazon-ebs.example:
amazon-ebs.example: PLAY RECAP *********************************************************************
amazon-ebs.example: 54.146.55.206 : ok=5 changed=3 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
amazon-ebs.example: 🧹 Cleaning up credential 63...
amazon-ebs.example: 🧹 Cleaning up host 66...
amazon-ebs.example: 🧹 Cleaning up inventory 75...
==> amazon-ebs.example: Stopping the source instance...
...
Build 'amazon-ebs.example' finished after 4 minutes 45 seconds.
==> Wait completed after 4 minutes 45 seconds
==> Builds finished. The artifacts of successful builds are:
--> amazon-ebs.example: AMIs were created:
us-east-1: ami-0d056993e3e2be56fHow the Plugin Integration Works
AAP has a well-documented REST API. The provisioner handles the entire lifecycle through API calls. Here’s the workflow:
sequenceDiagram
participant P as Packer
participant Prov as AAP Provisioner
participant AAP as Ansible Automation Platform
participant VM as Target VM
P->>Prov: Start provisioning
Prov->>AAP: Create temporary inventory
AAP-->>Prov: Inventory ID: 123
Prov->>AAP: Register target host
AAP-->>Prov: Host ID: 456
Prov->>AAP: Create SSH/WinRM credential
AAP-->>Prov: Credential ID: 789
Prov->>AAP: Launch job template
AAP-->>Prov: Job ID: 1001
loop Poll Status
Prov->>AAP: Check job status
AAP-->>Prov: Status: running/successful/failed
end
AAP->>VM: Execute playbooks
VM-->>AAP: Configuration complete
Prov->>AAP: Delete credential
Prov->>AAP: Delete host
Prov->>AAP: Delete inventory
Prov-->>P: Provisioning complete
1. Dynamic Inventory Creation
First, we create a temporary inventory in AAP. Every build receives its temporary inventory with a timestamp, ensuring no conflicts or stepping on other builds, providing clean isolation.
curl -X POST https://aap.example.com/api/controller/v2/inventories/ \
-H "Authorization: Bearer $AAP_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"name": "packer-inv-1642684800",
"description": "Temporary inventory for packer provisioning",
"organization": 1
}'Response:
{
"id": 123,
"name": "packer-inv-1642684800",
"organization": 1,
"created": "2025-01-20T10:00:00Z"
}2. Host Registration
Next, we register the target host that Packer is building. In the provisioner, we retrieve all connection details directly from Packer’s communicator. SSH keys, passwords, WinRM creds, whatever Packer is using to talk to the instance:
curl -X POST https://aap.example.com/api/controller/v2/hosts/ \
-H "Authorization: Bearer $AAP_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"name": "10.0.1.100",
"inventory": 123,
"variables": "{\"ansible_host\": \"10.0.1.100\", \"ansible_port\": 22, \"ansible_user\": \"ec2-user\"}"
}'Response:
{
"id": 456,
"name": "10.0.1.100",
"inventory": 123,
"variables": "{\"ansible_host\": \"10.0.1.100\", \"ansible_port\": 22, \"ansible_user\": \"ec2-user\"}"
}3. Dynamic Credential Management
Each build has the option to use a temporary credential provided to AAP; this refers to SSH key or username/password authentication.
curl -X POST https://aap.example.com/api/controller/v2/credentials/ \
-H "Authorization: Bearer $AAP_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"name": "packer-ssh-cred-1642684800",
"description": "SSH credential for Packer builds",
"credential_type": 1,
"organization": 1,
"inputs": {
"username": "ec2-user",
"ssh_key_data": "-----BEGIN PRIVATE KEY-----\nMIIEvgIBADANBgkqhkiG9w0BAQEFAASCBKgwggSkAgEAAoIBAQC..."
}
}'Response:
{
"id": 789,
"name": "packer-ssh-cred-1642684800",
"credential_type": 1,
"organization": 1
}4. Job Orchestration
Finally, we launch the actual job template. For this integration to work properly, your job template in AAP needs to be configured to accept runtime parameters:
{
"name": "Packer Image Build Template",
"ask_inventory_on_launch": true,
"ask_credential_on_launch": true,
"ask_variables_on_launch": true
}The ask_inventory_on_launch and ask_credential_on_launch settings are crucial – they allow the provisioner to inject the temporary inventory and credentials at launch time instead of using pre-configured values. Without these settings, the job template would try to use its default inventory and credentials, which won’t have access to your Packer-managed instance.
Here’s the launch request:
curl -X POST https://aap.example.com/api/controller/v2/job_templates/42/launch/ \
-H "Authorization: Bearer $AAP_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"inventory": 123,
"credentials": [789],
"extra_vars": {
"environment": "production",
"packer_build_name": "amazon-linux-base",
"packer_build_id": "build-1642684800"
}
}'Response:
{
"job": 1001,
"ignored_fields": {},
"id": 1001,
"type": "job",
"url": "/api/controller/v2/jobs/1001/",
"status": "pending"
}Then we poll the job status until completion:
curl -X GET https://aap.example.com/api/controller/v2/jobs/1001/ \
-H "Authorization: Bearer $AAP_TOKEN"Response when complete:
{
"id": 1001,
"status": "successful",
"finished": "2025-01-20T10:15:30Z",
"elapsed": 330.5
}Automated Resource Lifecycle Management
One of the more critical steps is to ensure that temporary resources are cleaned up. Nothing worse than finding 500 orphaned inventories in AAP because builds crashed. The provisioner is coded to track and clean up in a dependency-safe cleanup process:
# Delete credential first
curl -X DELETE https://aap.example.com/api/controller/v2/credentials/789/ \
-H "Authorization: Bearer $AAP_TOKEN"
# Then delete the host (depends on credential being removed)
curl -X DELETE https://aap.example.com/api/controller/v2/hosts/456/ \
-H "Authorization: Bearer $AAP_TOKEN"
# Finally delete the inventory (depends on hosts being removed)
curl -X DELETE https://aap.example.com/api/controller/v2/inventories/123/ \
-H "Authorization: Bearer $AAP_TOKEN"Get Started
Ready to integrate your Packer workflows with AAP? The provisioner is open source and available on GitHub. Check out the repository for installation instructions, configuration examples, and contribution guidelines:
rptcloud/packer-plugin-ansible-aap
If you’re using this provisioner in your environment or have ideas for improvements, contributions and feedback are welcome!
As organizations manage their digital transformation initiatives in today’s business world, their technology investments are often viewed under a microscope. Do they align with strategic objectives? Do they support the company’s innovation goals? Will they pose a business risk? And of course, how cost effective is the investment? Is it a financially responsible choice and what’s the ROI? When it comes to costs associated with protecting an organization’s vital resources, infrastructure, and data, many CTOs, CISOs, and CIOs have to weigh the cost of investment in new technologies vs relying on legacy systems that actually increase their exposure to nefarious actors.
The simple truth is that the typical security methods employed by many enterprises today often come with hidden costs: potential for costly breaches, increased vulnerability, wasted man-hours, and operational inefficiencies. This is where HashiCorp Vault and Boundary come in. When leveraged together they deliver a host of benefits, including cost optimization, streamlined workflows, simplified compliance, and of course they reduce the risk and minimize the financial impact of security incidents.
Understanding the Traditional Cost Conundrum
Before exploring how Vault and Boundary save money, let’s examine the cost burdens associated with traditional security approaches:
- Inefficient Access Management: Manual provisioning and management of passwords, access controls, and VPNs are time-consuming and error-prone, requiring additional IT resources and increasing operational costs.
- Scattered Configurations: Lack of centralized control leads to inconsistencies and vulnerabilities, requiring more resources for monitoring and maintenance, further adding to the expenses.
- Compliance Challenges: Manually handling compliance requirements can be complex and resource-intensive, potentially leading to non-compliance fines and reputational damage, both of which can be financially detrimental.
- Increased Downtime: Security breaches caused by weak access control or outdated methods can result in costly downtime, impacting productivity and revenue.
Cost-Saving Advantages of Vault and Boundary
By integrating Vault and Boundary, organizations can unlock cost-saving benefits without compromising their organization’s security posture:

- Reduced Administrative Burden:
- Automation Powerhouse: Vault automates secrets management tasks like generation, rotation, and revocation, while Boundary automates access control based on pre-defined policies. This frees up IT staff to focus on strategic innovations, reducing labor costs associated with manual processes.
- Centralized Control: Managing secrets and access from a single platform eliminates the need for managing scattered configurations across multiple systems, minimizing administrative overhead and associated fees.
- Enhanced Efficiency and Productivity:
- Streamlined Workflows: Automating tasks and simplifying access control processes improve efficiency for both the IT team and users, saving time and effort that can be directed towards more strategic endeavors.
- Reduced Downtime: By minimizing the attack surface and offering high availability through tools like Vault and Boundary, you can help prevent security breaches and related downtime, saving on costs associated with business disruptions and lost productivity.
- Simplified Compliance Management:

- Built-in Features: Both tools offer features and integrations that help organizations comply with industry standards and regulations, potentially reducing the need for additional tools or external expertise, leading to cost savings.
- Reduced Risk of Non-Compliance Fines: By simplifying and automating compliance efforts, Vault and Boundary can help organizations avoid potential fines and penalties associated with non-compliance, saving significant financial resources.
- Indirect Cost Savings:
- Enhanced Security: By minimizing the attack surface, reducing the impact of breaches, and enforcing least privilege principles, Vault and Boundary can help organizations avoid the financial costs associated with data breaches, including recovery efforts, reputational damage, and potential legal issues.
- Improved User Experience: Secure and streamlined access management can lead to increased user satisfaction and productivity, potentially reducing the need for user support and associated costs.

Long-Term Value Proposition:
While the upfront costs of acquiring and implementing Vault and Boundary should be considered, the opportunity for cost savings over the long term through increased efficiency, reduced downtime, improved security, and simplified compliance makes the investment financially sound.
By implementing HashiCorp Vault and Boundary together, organizations can optimize their financial investment in both platforms. Through automation, centralization, and streamlined workflows, these powerful tools empower organizations to achieve a balance between robust security and financial sustainability, paving the way for an organization to achieve long-term success in the ever-evolving digital world.
Need help maximizing the benefits of using Vault & Boundary? Contact the experts at RPT. As HashiCorp’s 2023 Global Competency of the Year and the only HashiCorp partner with all 3 certifications (Security, Infrastructure, & Networking), you know you’re working the leading HashiCorp services partner. Contact [email protected] today.
About River Point Technology
River Point Technology (RPT) is an award-winning cloud and DevOps service provider that helps Fortune 500 companies accelerate digital transformation and redefine what is possible. Our passionate team of engineers and architects simplify the deployment, integration, and management of emerging technology by delivering state-of-the-art custom solutions. We further position organizations to experience Day 2 success at scale and realize the value of their technology investments by offering best-in-class enablement opportunities. These include the subscription-based RPT Resident Accelerator program that’s designed to help enterprises manage the day-to-day operations of an advanced tech stack, the just-launched RPT Connect App, and our expert-led training classes. Founded in 2011, our unique approach to evaluating and adopting emerging technology is based on our proprietary and proven Value Creation Technology process that empowers IT teams to boldly take strategic risks that result in measurable business impact. What’s your vision? Contact River Point Technology today and see what’s possible.
By, Samuel Cadavid, Senior Solutions Consultant
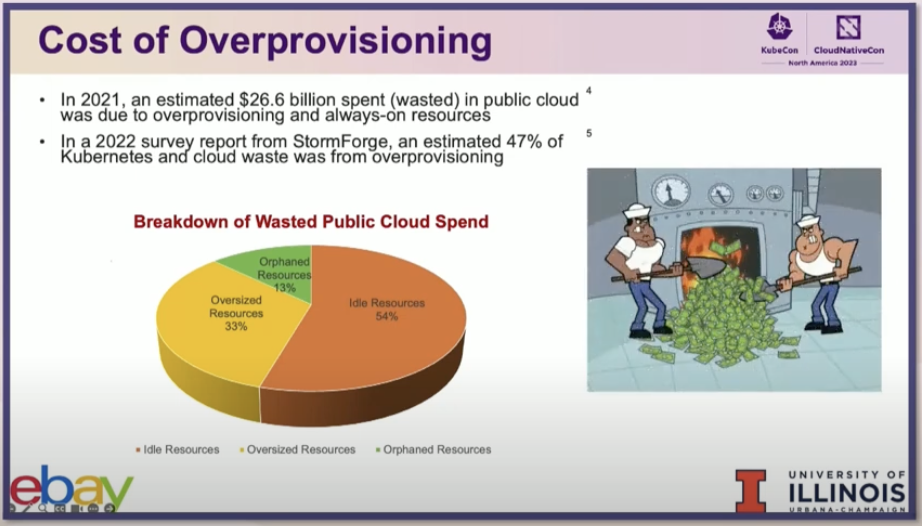
In the dynamic world of cloud computing,  Kubernetes has emerged as a frontrunner in orchestrating containerized applications. However, as the complexity and scale of deployments grow, managing resources efficiently becomes a daunting task. This is where Artificial Intelligence (AI) steps in, revolutionizing how we approach Kubernetes management, specifically in in-place pod resizing, vertical and horizontal scaling, and power-aware batch scheduling. During my recent trip to KubeCon, I was able to attend a session hosted by Vinay Kulkarni (eBay) and Haoran Qiu (UIUC) that delved into this topic, including how cluster autoscaler currently handles pods pending due to insufficient resources, changes to the autoscaling workflow that right-sizes over-provisioned pods, and the latest research that leverages machine learning to achieve multi-dimensional autoscaling. The session got me thinking about how AI plays a role in pod-resizing, and it inspired me to keep digging into it afterward.
Kubernetes has emerged as a frontrunner in orchestrating containerized applications. However, as the complexity and scale of deployments grow, managing resources efficiently becomes a daunting task. This is where Artificial Intelligence (AI) steps in, revolutionizing how we approach Kubernetes management, specifically in in-place pod resizing, vertical and horizontal scaling, and power-aware batch scheduling. During my recent trip to KubeCon, I was able to attend a session hosted by Vinay Kulkarni (eBay) and Haoran Qiu (UIUC) that delved into this topic, including how cluster autoscaler currently handles pods pending due to insufficient resources, changes to the autoscaling workflow that right-sizes over-provisioned pods, and the latest research that leverages machine learning to achieve multi-dimensional autoscaling. The session got me thinking about how AI plays a role in pod-resizing, and it inspired me to keep digging into it afterward.
AI-Driven In-Place Pod Resizing
Traditionally, resizing pods in Kubernetes meant recreating them with the new size specifications. This process, while effective, leads to downtime and potential service disruptions. AI-driven in-place pod resizing changes this narrative.
How it Works
AI algorithms continuously monitor the resource usage patterns of each pod. When a pod requires more resources, AI predicts this need and dynamically adjusts CPU and memory allocations without restarting the pod. This approach minimizes downtime and ensures that applications scale seamlessly with fluctuating demands.
Benefits 
- Reduced Downtime: Applications remain available as they’re resized.
- Resource Efficiency: Optimal resource allocation prevents over-provisioning and underutilization.
- Cost-Effectiveness: Efficient resource usage translates to lower operational costs.
Vertical and Horizontal Scaling: AI at the Helm
Vertical Scaling with AI
AI-driven vertical scaling involves adjusting the CPU and memory limits of a pod. Using predictive analytics, AI determines the optimal size for a pod based on historical data and current trends. This proactive resizing prevents resource exhaustion and improves performance.
Horizontal Scaling with AI
In horizontal scaling, AI plays a pivotal role in deciding when to add or remove pod instances. By analyzing traffic patterns, workload demands, and system health, AI can automate the scaling process, ensuring that the cluster meets the demand without manual intervention.
Advantages
- Proactive Resource Management: AI anticipates changes in demand, scaling resources accordingly.
- Improved Performance: Resources are optimized for current workloads, enhancing overall system efficiency.
- Autonomous Operations: Reduces the need for manual scaling, saving time and reducing human error. \
Power-Aware Batch Scheduling with AI
Energy efficiency is becoming increasingly important in data center operations. AI-driven power-aware batch scheduling in Kubernetes is a game-changer in this realm.
The Concept
This approach involves scheduling batch jobs in a manner that optimizes power usage. AI algorithms analyze the power consumption patterns of nodes and schedule jobs on those consuming less power or during off-peak hours, significantly reducing the overall energy footprint.
Impact
- Energy Efficiency: Lower power consumption leads to a reduced carbon footprint and operational costs.
- Optimized Performance: Ensures that high-power-consuming jobs don’t coincide, avoiding power spikes and potential performance degradation.
- Sustainable Operations: Supports environmentally friendly practices in data center management.
The integration of AI into Kubernetes management is not just a trend; it’s a necessity for efficient, cost-effective, and sustainable operations. AI’s role in in-place pod resizing, vertical and horizontal scaling, and power-aware batch scheduling marks a significant leap towards smarter, more autonomous cloud infrastructures. As we continue to embrace these AI-driven strategies, we pave the way for more resilient, responsive, and responsible computing environments. Here, I’ve only scratched the surface of what AI can do for Kubernetes management. As technology evolves, we can expect even more innovative solutions to emerge, further simplifying and enhancing the way we manage cloud resources.
Watch the full lecture here!
