Since the mid-2000s, organizations have enthusiastically embraced DevOps, reaping the rewards of collaborative synergy between software development and operations teams. However, progress doesn’t come without challenges. Along their journey of digital evolution, many organizations have opted for multiple DevOps platforms. While the reasons for doing so may have been compelling at the time, they now find themselves facing a conundrum. Unknowingly, they have put their companies at risk, wasted valuable resources, and unintentionally hampered their teams’ efficiency. Read on to learn about the top 8 risks of using too many DevOps platforms.

Complexity: Every DevOps platform has its own set of features, workflows, and integrations. This makes it harder for your teams to manage and maintain your overall infrastructure. Staff will also need additional training to operate and integrate the platforms and ensure a smooth coordination between them all. In short, you create a management nightmare.

Increased Costs: From licenses and training to support, platform costs add up! Every platform comes with its own licensing or subscription fees. You may even miss out on better pricing.

Security Risks: You may not realize it, but too many DevOps platforms also makes you more vulnerable to data breaches and security risks. If you’re not careful, you could unknowingly expose your applications to vulnerabilities by using different platforms that have differing security features.

Compliance Risks: When you’re using different platforms with different protocols and practices, you make maintaining compliance with industry regulations more challenging. Each platform can have different security measures, access controls, and audit logs. It becomes harder and harder to monitor compliance across the organization.

Incompatibility / Integration Problems: Some DevOps platforms don’t play nice with others. This can make it difficult to integrate your development and deployment processes, which negates the reason why you undertook a DevOps strategy in the first place. It can waste valuable man-hours as it can lead to errors and downtime.

Fragmented Processes: Because each platform can have its own set of practices and tools, it can be a challenge to collaborate, share knowledge, and ensure efficient workflows across the organization. This wastes valuable resources and can cause frustration across all business units.

Skill Diversification & Learning Curve: If you have five different DevOps platforms, you have that many platforms to train and upskill your team on. Teams need to adapt to different tools and workflows, they need greater skill diversification and it becomes all that more difficult to build deep expertise specialization in a specific platform or toolset.

Maintenance & Support Challenges: It can be incredibly resource intensive to support multiple DevOps platforms. Updates, bug fixes, and support requests for each platform require dedicated effort and expertise. Many organizations struggle to manage it all.
No doubt, the negative implications associated with DevOps tool sprawl are real. That’s why many 0rganizations that have found themselves in the multi DevOps platforms dilemma are opting to consolidate all their platforms and having a centralized one. But what’s that process like and how do you choose the best single DevOps platform to migrate to? Read this Case Study for more answers.
Stress is a pervasive issue that affects people from all walks of life, including those in the business world. Unfortunately, the effects of stress on businesses in America can be detrimental, impacting productivity, morale, and even the bottom line.
The American Institute of Stress estimates that stress costs businesses in the United States approximately $300 billion per year in absenteeism, turnover, decreased productivity, and healthcare costs.
Stress can lead to increased absenteeism and turnover rates in businesses. Employees who are stressed may take more sick days, be less productive when they are at work, and ultimately leave the company if their stress levels become too overwhelming. This can lead to decreased productivity, decreased morale, and increased costs associated with recruitment and training of new employees.
Employees’ health can also be affected by stress, leading to increased healthcare costs for the company. Those who are stressed may be more likely to experience physical or mental health issues, such as anxiety, depression, and cardiovascular disease. This can lead to increased absenteeism and disability claims, which can increase the overall cost of healthcare for the company.
According to the National Institute for Occupational Safety and Health, 40% of workers reported their job was very or extremely stressful.
Stress can have a significant impact on businesses in America, leading to decreased productivity, increased absenteeism and turnover, negative impact on morale, and increased healthcare costs. This is why RPT takes steps to manage stress in the workplace, by helping their employees maintain their health and well-being while also improving productivity and overall company success.
- 401k
- Unlimited PTO
- Work from here or home
- Parental leave
- Insurance benefits
- Opportunities to give back
- Professional development
- Quarterly bonus program
- Unlimited in-office refreshments
This includes providing resources for stress management, promoting work-life balance, creating a positive work environment, and encouraging open communication between employees and management. Learn more about joining the RPT team here!
Introduction to Secrets Management
By, Bryan Krausen: Author, Instructor, and VP, Consulting Services at RPT
So why is secrets management so important? Regardless of the type of environment you work in, there will be privileged credentials needed by applications, users, or other software platforms to manage your environment. Secrets can be anything your organization deems confidential and could cause harm to the company if shared or exposed. Examples could be database credentials to read customer data, a private key used to decrypt communications to your app server, or domain admin creds used by your vulnerability scanner during nightly runs. Managing these privileged credentials is an essential process that is critical to an organization’s security posture.
Secrets are used EVERYWHERE in organizations. Think about the credentials that were required for the last application or deployment you participated in, regardless of how basic or complex it was. As a human user, you likely need privileged credentials to provision resources in your production environment, like gaining access to VMware vCenter to deploy virtual machines, requesting a TLS certificate for your application, or logging into Terraform Cloud to provision Amazon EC2 instances. Moving over to the application side, they need access to additional services within your organization, like an internal API, a file share, or the ability to read/write to a database server to store data. The applications might need to register the service within your service catalog (service mesh) or execute a script that traverses a proxy and pulls down packages from Artifactory. These actions all require some privileged credential or secret that needs to be managed appropriately.
Consolidation of Secrets
So where should all these secrets live? Most organizations understand these secrets should be managed in some secret management solution. However, that doesn’t always reflect what is actually in practice. I’ve worked with countless organizations that keep credentials in an Excel sheet, a OneNote document, or even a text file on their desktop. That strategy provides absolutely no security and exposes these companies to security breaches. Other organizations have taken a step further and used a consumer-based solution, like 1Password or LastPass, to store these long-lived credentials. It’s better than nothing, but it doesn’t provide the organization with complete visibility and management of credentials. Plus, we’re talking about the practice of DevOps here, so it doesn’t offer much in terms of automated retrieval or rotation either.
Ideally, organizations need to adopt a proper secret management tool that can be used to consolidate secrets and provide features such as role-based access control, rotation and revocation, expiration, and auditing capabilities.
Long-Lived Secrets vs. Dynamic Secrets
Let’s talk about the difference between long-lived secrets and dynamic secrets.
Long-Lived Credentials
Not all secrets are created equal. Most organizations default to creating long-lived, static credentials that are often shared among teams and applications. Creating these credentials usually requires a long process, such as ticket creation, security approval, management approval, etc. Because obtaining credentials is often tedious, engineers and administrators will reuse or share these credentials among different applications rather than repeat this process. Be honest, how many times have you clicked this button in Active Directory? I know I have done it 100s of times in the past….
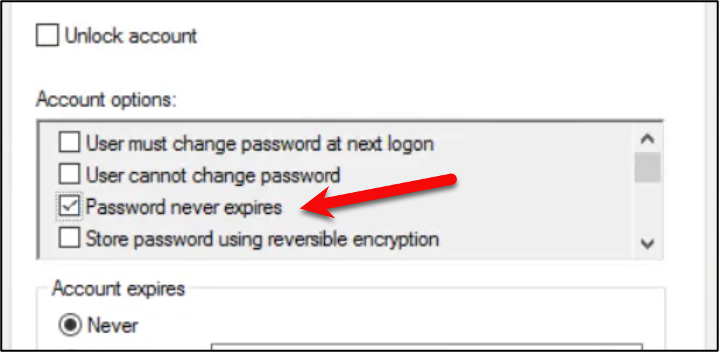
These reused and often shared credentials are hard to audit, can be impossible to rotate, and provide very little accountability. Additionally, these static credentials offer 24/7 access to the target system, even though access might only be needed for minutes per day.
Dynamic Secrets
In contrast with static credentials, many organizations realize the benefits of migrating to dynamically generated secrets. Rather than create the credentials beforehand, applications can request credentials on-demand when needed. The application uses dynamic credentials to access a system or platform to perform work, and the credentials are then revoked/deleted afterward. If these dynamic credentials are accidentally written to a log file or committed to a code repository, it no longer becomes a security threat because they are already invalidated. And because dynamic credentials are accessible to applications (with proper authentication, of course), each instance of an application can generate its own credential to access the backend system.
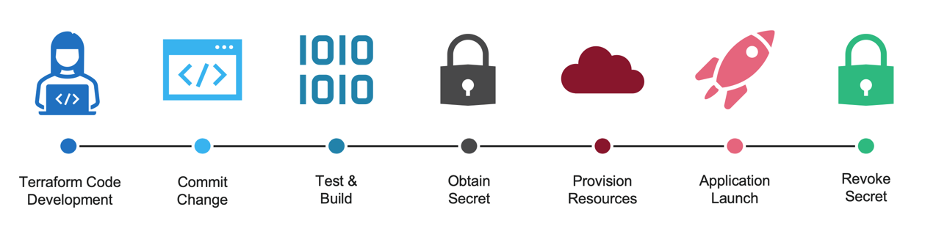
For example, let’s assume we’re using Terraform to deploy our infrastructure to our favorite public cloud platform. If you were using static credentials, you would log into the cloud platform, create static credentials (probably highly privileged ones), and provide those credentials for Terraform to provision and manage your infrastructure. Those highly privileged credentials are valid 24/7, even though you only run Terraform a few times daily. On the other hand, if you were using a dynamic credential, Terraform could first obtain a credential, provision, or manage the infrastructure, and the credential would be invalidated after. When Terraform isn’t running, there is no credential that can be exposed or misused. Even if the dynamic credential were written to logs or accidentally committed to a public GitHub repo, it wouldn’t matter since it was revoked when the job was completed or after a minimal TTL.
Access Control and Auditing of Secrets
Access to secrets should be tightly controlled, and only authorized personnel should be able to access them. Ideally, two-factor authentication or a multi-step approval process should be in place for highly-privileged credentials, such as domain access, root credentials, or secrets used to obtain confidential data. Access should be limited to secrets based on an employee’s role within the organization or an application’s requirements to fulfill its duties.
It is important that access to secrets should be closely monitored, and a log should be maintained of all actions taken of them. Logs should be ingested into a SIEM or log correlation systems, like Splunk, SumoLogic, or DataDog, to create dashboards and alert on specific actions. This can help quickly detect and respond to potential security threats within the organization.
Common Secrets Management Solutions
In a DevOps and automated world, secrets management solutions must be centered around a fully featured REST API. With such, access to the platform can be automated entirely by any orchestrator or pipeline tool the organization uses, simplifying company-wide adoption. Secrets Management tools such as HashiCorp Vault, AWS Secrets Manager, or Azure Key Vault can provide organizations with features such as encryption at rest, role-based access control, and auditing capabilities to help protect secrets. From my experience, the most popular tools used by organizations are:
- HashiCorp Vault
- CyberArk
- AWS Secrets Manager
- Azure Key Vault
- GCP Secret Manager
- Thycotic Secret Server
###
How safe is your cloud infrastructure? The team at River Point Technology consists of top experts who are the IT industry’s best at securing, storing and controlling secrets in the cloud. Our approach is centered around helping our clients achieve maximum value out of their technology investments. Contact us today for a security assessment.