HashiCorp’s Terraform Cloud provides a centralized platform for managing infrastructure as code. It’s a leading provider in remote Terraform management with remote state management, automated VCS integrations, and cost visibility. One of its features, a private registry, can be used to develop internal Terraform providers where control, security, and customizations are paramount.
Let’s explore an example using the Terraform Provider Scaffolding Framework to build a custom Terraform provider and publish it to a private registry. Scaffold provides a framework starter kit that you can use out of the box to replace your APIs.
Signing Your Provider
Code signing guarantees that the generated artifacts originate from your source, allowing users to verify this authenticity by comparing the produced signature with your publicly available signing key. It will require you to generate a key pair through the GNU PGP utility. You can develop this by using the command below, be sure to replace GPG_PASSWORD and your name with values that make sense.
gpg --default-new-key-algo rsa4096 --batch --passphrase "${GPG_PASSWORD}" --quick-gen-key 'Your Name <[email protected]>' default defaultExport Public Key
With your newly generated key securely stored, the next step involves exporting and uploading it to Terraform Cloud. This action facilitates verification while deploying your signed artifacts, and ensuring their authenticity within the platform’s environment. The GPG Key API requires the public key to validate the signature. To access the list of key IDs, you can execute: gpg --list-secret-keys --keyid-format LONG. The key is denoted in the output.
[keyboxd]
---------
sec rsa4096/<KEY ID> 2023-11-22 [SC] [expires: 2026-11-21]You can then get your public key as a single string. KEY=$(gpg --armor --export ${KEY_ID} | awk '{printf "%sn", $0}'). You’ll then need to build a payload with the output of that file and POST that to https://app.terraform.io/api/registry/private/v2/gpg-keys. The ORG_NAME is your Terraform cloud organization.
{
"data": {
"type": "gpg-keys",
"attributes": {
"namespace": "${ORG_NAME}",
"ascii-armor": "${KEY}"
}
}
}Export Private Key for CI/CD (Optional)
If you plan to use this key in a CI Platform, you can also export the key and upload it gpg --export-secret-keys --armor ${KEY_ID} > /tmp/gpg.pgp to a secure Vault.
Packaging Terraform Providers with GoReleaser
GoReleaser simplifies the process of building and releasing Go binaries. Using GoReleaser, we can bundle different architectures, operating systems, etc.
You will need to create a terraform registry manifest, the protocol version is essential. If you are using Plugin Framework, you will want version 6.0. If you are using Plugin SDKv2, you will want version 5.0.
{
"version": 1,
"metadata": {
"protocol_versions": ["6.0"]
}
}Configuring GoReleaser
Ensure your goreleaser.yml configuration includes settings for multi-architecture support and signing. This file should live at the provider’s root, next to your main codebase.
before:
hooks:
- go mod tidy
builds:
- env:
- CGO_ENABLED=0
mod_timestamp: '{{ .CommitTimestamp }}'
flags:
- -trimpath
ldflags:
- '-s -w -X main.version={{ .Version }} -X main.commit={{ .Commit }}'
goos:
- freebsd
- windows
- linux
- darwin
goarch:
- amd64
- '386'
- arm
- arm64
ignore:
- goos: darwin
goarch: '386'
binary: '{{ .ProjectName }}_v{{ .Version }}'
archives:
- format: zip
name_template: '{{ .ProjectName }}_{{ .Version }}_{{ .Os }}_{{ .Arch }}'
checksum:
extra_files:
- glob: 'terraform-registry-manifest.json'
name_template: '{{ .ProjectName }}_{{ .Version }}_manifest.json'
name_template: '{{ .ProjectName }}_{{ .Version }}_SHA256SUMS'
algorithm: sha256
signs:
- artifacts: checksum
args:
- "--batch"
- "--local-user"
- "{{ .Env.GPG_FINGERPRINT }}"
- "--output"
- "${signature}"
- "--detach-sign"
- "${artifact}"
stdin: '{{ .Env.GPG_PASSWORD }}'
release:
extra_files:
- glob: 'terraform-registry-manifest.json'
name_template: '{{ .ProjectName }}_{{ .Version }}_manifest.json'
changelog:
skip: trueTag your Branch
git tag 0.0.1
git checkout 0.0.1Your git strategy may differ, but GoReleaser uses branch tags to determine versions.
Bundle and Sign Binaries
Execute GoReleaser to bundle the binaries locally without publishing. We skipped publishing as we will manually upload them to Terraform Cloud.
export GPG_TTY=$(tty)
export GPG_FINGERPRINT=${KEY_ID}
goreleaser release --skip=publish
Now we have our artifacts.
Publishing to Terraform Cloud Private Registry
Once you have the signed binaries, you can publish them to the Terraform Cloud private registry. HashiCorp provides a guide, which we will follow.
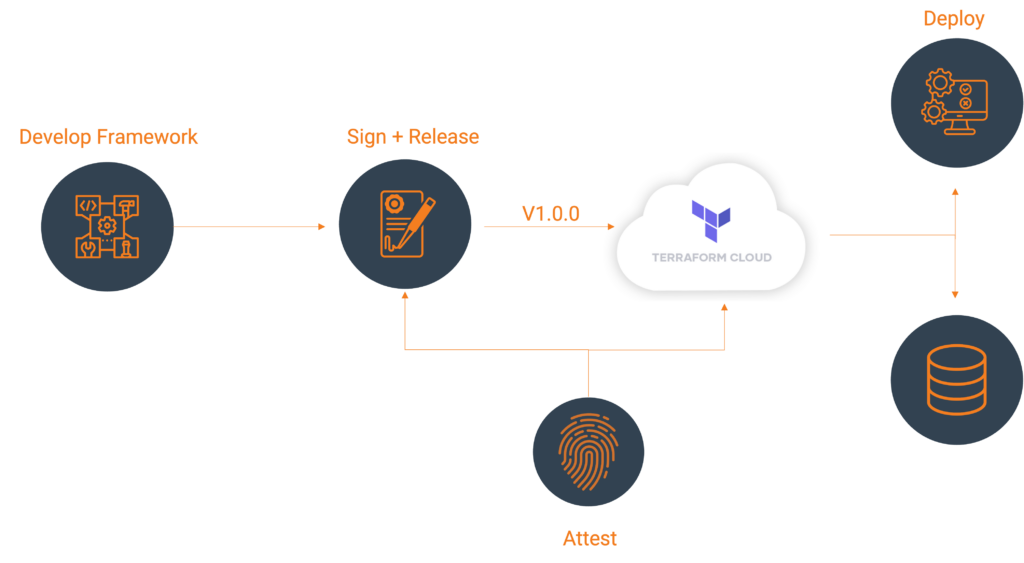
Register the provider (first time only)
Create a provider config file and POST that body utilizing your Terraform Cloud API token. A provider name is usually a singular descriptor representing a business unit, such as Google or AWS.
curl --header "Authorization: Bearer ${TERRAFORM_CLOUD_API_TOKEN}"
--header "Content-Type: application/vnd.api+json"
--request POST
-d @-
"https://app.terraform.io/api/v2/organizations/${ORG_NAME}/registry-providers" <<EOT
{
"data": {
"type": "registry-providers",
"attributes": {
"name": "${PROVIDER_NAME}",
"namespace": "${ORG_NAME}",
"registry-name": "private"
}
}
}
EOTUploading your Versions
Create Version Shell within Private Registry Providers
curl -H "Authorization: Bearer ${TOKEN}"
-H "Content-Type: application/vnd.api+json"
--request POST
-d @-
"https://app.terraform.io/api/v2/organizations/${ORG_NAME}/registry-providers/private/${ORG_NAME}/${PROVIDER_NAME}/versions" <<EOT
{
"data": {
"type": "registry-provider-versions",
"attributes": {
"version": "${VERSION}",
"key-id": "${KEY_ID}",
"protocols": ["6.0"]
}
}
}
EOTThe response will contain upload links that you will use to upload the SHA256SUMS and SHA256.sig files.
"links": {
"shasums-upload": "https://archivist.terraform.io/v1/object/dmF1b64hd73ghd63",
"shasums-sig-upload": "https://archivist.terraform.io/v1/object/dmF1b37dj37dh33d"
}Upload Signatures.
# Replace ${VERSION} and ${PROVIDER_NAME} with actual values
curl -sS -T "dist/terraform-provider-${PROVIDER_NAME}_${VERSION}_SHA256SUMS" "${SHASUM_UPLOAD}"
curl -sS -T "dist/terraform-provider-${PROVIDER_NAME}_${VERSION}_SHA256SUMS.sig" "${SHASUM_SIG_UPLOAD}"Register Platform for every Architecture and Operating System.
FILENAME="terraform-provider-${PROVIDER_NAME}_${VERSION}_${OS}_${ARCH}.zip"
SHA=$(shasum -a 256 "dist/${FILENAME}" | awk '{print $1}' )
# OS ex. darwin/linux/windows# ARCH ex. arm/amd64# FILENAME. terraform-provider-<PROVIDER_NAME>_<VERSION>_<OS>_<ARCH>.zip. Define through name_template
curl -H "Authorization: Bearer ${TOKEN}"
-H "Content-Type: application/vnd.api+json"
--request POST
-d @-
"https://app.terraform.io/api/v2/organizations/${ORG_NAME}/registry-providers/private/${ORG_NAME}/${PROVIDER_NAME}/versions/${VERSION}/platforms" << EOT
{
"data": {
"type": "registry-provider-version-platforms",
"attributes": {
"shasum": "${SHA}",
"os": "${OS}",
"arch": "${ARCH}",
"filename": "${FILENAME}"
}
}
}
EOTThe response will contain upload the provider binary to:
"links": {
"provider-binary-upload": "https://archivist.terraform.io/v1/object/dmF1b45c367djh45nj78"
}Upload archived binaries
curl -sS -T "dist/${FILENAME}" "${PROVIDER_BINARY_URL}"Repeat step: Register Platform for every Architecture and Operating System and step: Upload Archived Binaries for every architecture and operating system.
Using the provider
Private providers hosted within Terraform Cloud are only available to users within the organization.
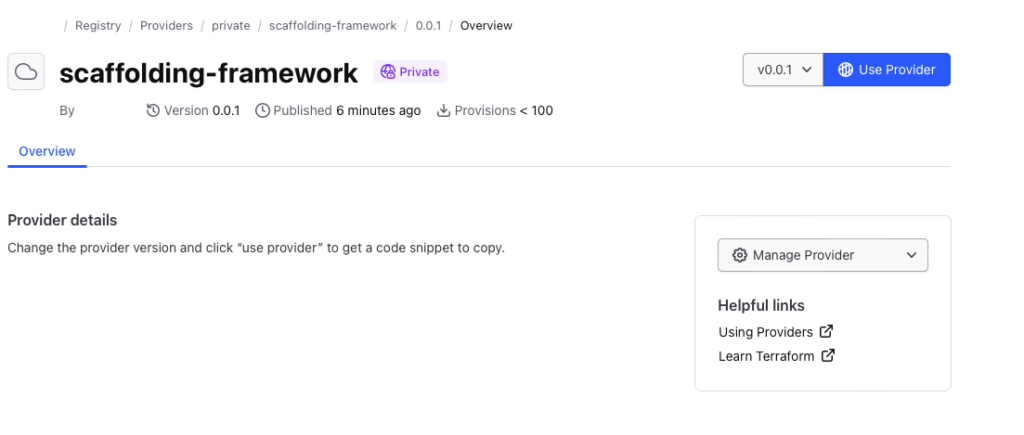
When developing locally, ensure you set up credentials through the terraform login, creating a credentials.tfrc.json file.
With the authentication bits setup, you can utilize the new provider by defining the provider block substituting in those existing variables.
terraform {
required_providers {
${PROVIDER_NAME} = {
source = "app.terraform.io/${ORG_NAME}/${PROVIDER_NAME}"
version = "${VERSION}"
}
}
}
provider "${PROVIDER_NAME}" {
# Configuration options
}Document Provider
For user consumption, a common practice is to provide provider documentation for your resources utilizing Terraform plugin docs. This plugin generator allows you to generate markdowns from examples and schema definitions, which users can then consume. At the time of publication, this feature is currently not supported within the Terraform Cloud. Please talk to your River Point Technology representative for alternative solutions.
Cleanup
To remove the provider from the registry:
Delete version
curl -H "Authorization: Bearer ${TOKEN}"
--request DELETE
"https://app.terraform.io/api/v2/organizations/${ORG_NAME}/registry-providers/private/${ORG_NAME}/${PROVIDER_NAME}/versions/${VERSION}"Delete provider
curl -H "Authorization: Bearer ${TOKEN}"
--request DELETE
"https://app.terraform.io/api/v2/organizations/${ORG_NAME}/registry-providers/private/${ORG_NAME}/${PROVIDER_NAME}"Deregister GPG Key
curl -H "Authorization: Bearer ${TOKEN}"
--request DELETE
https://app.terraform.io/api/registry/private/v2/gpg-keys/${ORG_NAME}/${KEY_ID}Conclusion
With a private registry, you get all the benefits of Terraform while still allowing internal consumption. This may be desirable when public providers don’t meet your use case and it comes with a host of benefits:
- More Customization and Control: A private registry allows organizations to maintain control over their proprietary or custom-built Terraform providers. It enables them to manage, version, and distribute these providers securely within the organization.
- Better Security and Compliance: A private registry ensures that only authorized users within the organization can access and utilize specific Terraform providers for sensitive or proprietary infrastructure configurations. This control aids in compliance with internal policies and regulatory requirements.
- Improved Versioning and Stability: With a private registry, teams can maintain a stable versioning system for their Terraform providers. This helps ensure project infrastructure configurations remain consistent and compatible with the specified provider versions.
Publishing custom Terraform providers to the Terraform Cloud private registry involves bundling, signing, and uploading binaries and metadata through the API. Following these steps, you can effectively manage and distribute your Terraform provider to support various architectures and operating systems.
River Point Technology (RPT) is here to guide you through the intricacies of exploring the dynamic cloud landscape. If you’re facing challenges and need assistance in achieving increased customization and oversight, enhanced security and compliance, along with improved versioning and stability, feel free to leave a comment or reach out to us directly.
As the HashiCorp Global Competency Partner of the Year and the only company certified in all three competencies—Security, Networking, and Infrastructure—we stand out as a market leader. Trusted by Fortune 500 companies, we serve as their guide in effectively navigating the dynamic cloud terrain. Contact RPT for guidance in optimizing the journey through the cloud landscape.
By, Samuel Cadavid, Senior Solutions Consultant
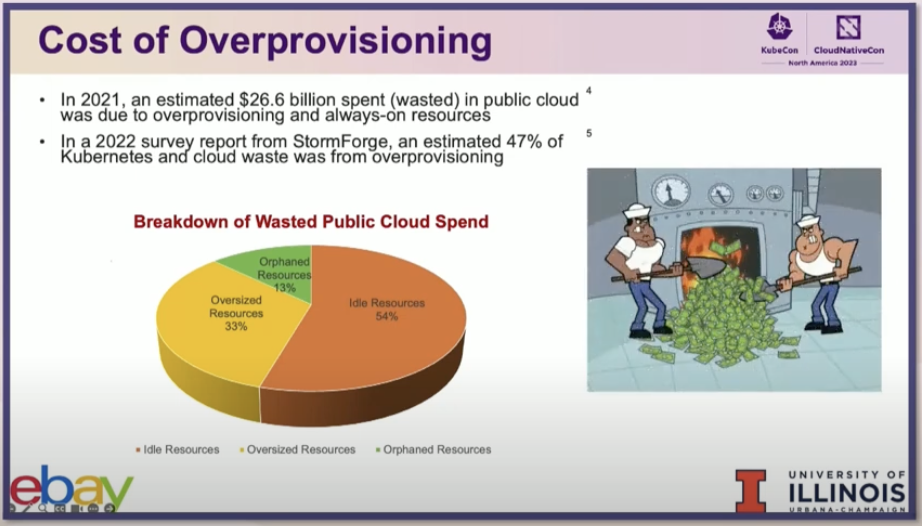
In the dynamic world of cloud computing,  Kubernetes has emerged as a frontrunner in orchestrating containerized applications. However, as the complexity and scale of deployments grow, managing resources efficiently becomes a daunting task. This is where Artificial Intelligence (AI) steps in, revolutionizing how we approach Kubernetes management, specifically in in-place pod resizing, vertical and horizontal scaling, and power-aware batch scheduling. During my recent trip to KubeCon, I was able to attend a session hosted by Vinay Kulkarni (eBay) and Haoran Qiu (UIUC) that delved into this topic, including how cluster autoscaler currently handles pods pending due to insufficient resources, changes to the autoscaling workflow that right-sizes over-provisioned pods, and the latest research that leverages machine learning to achieve multi-dimensional autoscaling. The session got me thinking about how AI plays a role in pod-resizing, and it inspired me to keep digging into it afterward.
Kubernetes has emerged as a frontrunner in orchestrating containerized applications. However, as the complexity and scale of deployments grow, managing resources efficiently becomes a daunting task. This is where Artificial Intelligence (AI) steps in, revolutionizing how we approach Kubernetes management, specifically in in-place pod resizing, vertical and horizontal scaling, and power-aware batch scheduling. During my recent trip to KubeCon, I was able to attend a session hosted by Vinay Kulkarni (eBay) and Haoran Qiu (UIUC) that delved into this topic, including how cluster autoscaler currently handles pods pending due to insufficient resources, changes to the autoscaling workflow that right-sizes over-provisioned pods, and the latest research that leverages machine learning to achieve multi-dimensional autoscaling. The session got me thinking about how AI plays a role in pod-resizing, and it inspired me to keep digging into it afterward.
AI-Driven In-Place Pod Resizing
Traditionally, resizing pods in Kubernetes meant recreating them with the new size specifications. This process, while effective, leads to downtime and potential service disruptions. AI-driven in-place pod resizing changes this narrative.
How it Works
AI algorithms continuously monitor the resource usage patterns of each pod. When a pod requires more resources, AI predicts this need and dynamically adjusts CPU and memory allocations without restarting the pod. This approach minimizes downtime and ensures that applications scale seamlessly with fluctuating demands.
Benefits 
- Reduced Downtime: Applications remain available as they’re resized.
- Resource Efficiency: Optimal resource allocation prevents over-provisioning and underutilization.
- Cost-Effectiveness: Efficient resource usage translates to lower operational costs.
Vertical and Horizontal Scaling: AI at the Helm
Vertical Scaling with AI
AI-driven vertical scaling involves adjusting the CPU and memory limits of a pod. Using predictive analytics, AI determines the optimal size for a pod based on historical data and current trends. This proactive resizing prevents resource exhaustion and improves performance.
Horizontal Scaling with AI
In horizontal scaling, AI plays a pivotal role in deciding when to add or remove pod instances. By analyzing traffic patterns, workload demands, and system health, AI can automate the scaling process, ensuring that the cluster meets the demand without manual intervention.
Advantages
- Proactive Resource Management: AI anticipates changes in demand, scaling resources accordingly.
- Improved Performance: Resources are optimized for current workloads, enhancing overall system efficiency.
- Autonomous Operations: Reduces the need for manual scaling, saving time and reducing human error. \
Power-Aware Batch Scheduling with AI
Energy efficiency is becoming increasingly important in data center operations. AI-driven power-aware batch scheduling in Kubernetes is a game-changer in this realm.
The Concept
This approach involves scheduling batch jobs in a manner that optimizes power usage. AI algorithms analyze the power consumption patterns of nodes and schedule jobs on those consuming less power or during off-peak hours, significantly reducing the overall energy footprint.
Impact
- Energy Efficiency: Lower power consumption leads to a reduced carbon footprint and operational costs.
- Optimized Performance: Ensures that high-power-consuming jobs don’t coincide, avoiding power spikes and potential performance degradation.
- Sustainable Operations: Supports environmentally friendly practices in data center management.
The integration of AI into Kubernetes management is not just a trend; it’s a necessity for efficient, cost-effective, and sustainable operations. AI’s role in in-place pod resizing, vertical and horizontal scaling, and power-aware batch scheduling marks a significant leap towards smarter, more autonomous cloud infrastructures. As we continue to embrace these AI-driven strategies, we pave the way for more resilient, responsive, and responsible computing environments. Here, I’ve only scratched the surface of what AI can do for Kubernetes management. As technology evolves, we can expect even more innovative solutions to emerge, further simplifying and enhancing the way we manage cloud resources.
Watch the full lecture here!

By Dan Quackenbush
In the dynamic world of tech conferences, there exists a gem unlike any other – KubeCon, where the orchestrators of Kubernetes gather to share tales of triumph and innovation. As a seasoned navigator of cluster administration, I found myself immersed in the heartbeat of this dynamic symphony of ideas, particularly drawn to the stories that unfolded after the initial deployment – the fascinating Day 2 Operations.
The first stop, Major League Baseball + Argo CD: A Home Run, implemented GitOps through Argo CD to empower feature-driven development using Helm charts. The stage was set with a compelling case study, highlighting how developers were handed the reins to their applications without drowning in the sea of YAML configurations. Through the power of abstraction, Helm deployed through Argo, allows them to focus on features, such as enabling monitoring, injecting secrets, and exposing their services across two hundred clusters, bringing consistency to the service runtime landscape.
 Next up was a talk on the alpha feature introduced in Kubernetes 1.27 – In-Place Resource Resize. A meaningful change for administrators dealing with dynamic resource-intensive applications, especially those built on JVM. Sustainable Scaling of Kubernetes Workloads with In-Place Pod Resize and Predictive AI, unfolded the power of dynamically adjusting pod sizes, unveiling a new level of flexibility for Kubernetes clusters. It was not about vertical scaling; but talked about how we could use ML to power these configurations without over-allocating resources.
Next up was a talk on the alpha feature introduced in Kubernetes 1.27 – In-Place Resource Resize. A meaningful change for administrators dealing with dynamic resource-intensive applications, especially those built on JVM. Sustainable Scaling of Kubernetes Workloads with In-Place Pod Resize and Predictive AI, unfolded the power of dynamically adjusting pod sizes, unveiling a new level of flexibility for Kubernetes clusters. It was not about vertical scaling; but talked about how we could use ML to power these configurations without over-allocating resources.
The talk FinOps at Grafana Labs illuminated the path to financial accountability, transforming it into a cultural cornerstone. The speaker painted a vivid picture of a world where accountability, transparency, and a culture of openness were the guiding lights. Through real-world examples, the audience learned the impact of “cash positive chaos testing,” moving to spot instances, aligning cost optimization measured against service reliability, and the importance of continuously stress-testing applications in various infrastructure conditions.
In a creative twist, Burden to Bliss: Eliminate Patching and Upgrading Toil with Cluster Autoscaler at Scale, dived into leveraging Cluster Autoscaler for applying security patches. The ingenious strategy involved creating new node pools and strategically shifting pods with tolerations to the patched nodes. By creating new node pools with the patched system and strategically forcing a single pod with toleration to the patched node, the talk demonstrated how eventual consistency mechanisms could be leveraged to shift all pods to the new node through eviction. This innovative strategy ensures that security patches are seamlessly applied without affecting ongoing workloads.
The final act in this symphony of talks explored the intersection of Kubernetes, service mesh, and content delivery networks (CDNs). Take It to the Edge: Creating a Globally Distributed Ingress with Istio & K8gb,  unveiled the critical role of service mesh in handling disruptions during DNS load balancing, offering a solution to the dreaded 502 errors. Through health checks and local failover endpoints, the talk unfolded how Kubernetes Global Balancer could redefine CDN construction, providing a resilient and scalable solution for distributed applications.
unveiled the critical role of service mesh in handling disruptions during DNS load balancing, offering a solution to the dreaded 502 errors. Through health checks and local failover endpoints, the talk unfolded how Kubernetes Global Balancer could redefine CDN construction, providing a resilient and scalable solution for distributed applications.
It is always interesting to hear how people are handling similar problems. These talks show us, how as a Kubernetes administrator, with a new mindset, can provide a central way for developers to be feature vs configuration driven, scale those workloads either in place, or through cheaper means, all while reducing the burden on sustainability. Once deployed, these applications can then spread across regions, on hardened nodes. I invite you to check out the talks, dive into the dynamic Day 2 Operations, and discover the secrets shared by industry leaders.