
Many infrastructure teams rely on powerful CLI tools. However these tools are often limited to experts who already understand the commands and workflows. At scale this creates a gap between capability and accessibility.
IBM Watsonx Orchestrate lets you build AI agents that can call tools through natural language. Instead of rewriting those tools, you can wrap your existing binaries as Python tools and expose them directly to Watsonx.
User -> Watsonx Agent -> Python Tool (@tool) -> CLI Binary -> Output -> Agent -> UserThe Problem
At River Point Technology, we have migrated many Terraform Enterprise organizations to HCP Terraform, spanning more than 1,500 workspaces. Our solutions architects have developed a custom CLI to handle complex migration steps with copying workspaces, variables, state files, teams, and policy sets between organizations. The CLI works well, but it assumes command-line fluency. We wanted the same migration engine available through a guided, conversational workflow so more teams could run tasks safely.
How Watsonx Tools Work
Watsonx tools are Python functions decorated with @tool from the ibm_watsonx_orchestrate SDK. Tool functions are a thin wrapper that takes agent-supplied parameters, maps them to your binary’s flags and environment variables, executes the command with subprocess, and returns output for the agent to summarize. The agent reads the function and docstring to understand what the tool does and when to call it. To deploy a tool, package your Python file, dependencies, and (in our case) the compiled binary, then upload everything with the orchestrate CLI.
Prerequisites
Before you start, make sure you have:
- Python tool code using the ibm-watsonx-orchestrate SDK
- A Linux build of your binary (watsonx sandbox runtime is Linux)
- orchestrate CLI access configured for your Watsonx tenant
Writing a Tool That Wraps a Binary
Here is a trimmed-down version of our skill. The full file has 25 tools covering the list, copy, lock, unlock, validate, and core migration commands.
import os
import stat
import subprocess
from pathlib import Path
from ibm_watsonx_orchestrate.agent_builder.tools import tool
BINARY = Path(__file__).parent / "skybridge"
def run(args: list[str]) -> str:
BINARY.chmod(BINARY.stat().st_mode | stat.S_IEXEC | stat.S_IXGRP | stat.S_IXOTH)
result = subprocess.run(
[str(BINARY), "--json", *args],
capture_output=True,
text=True,
env=os.environ.copy(),
)
if result.returncode != 0:
return f"[exit {result.returncode}]\nSTDOUT: {result.stdout}\nSTDERR: {result.stderr}"
return result.stdout or result.stderr
@tool
def skybridge_copy_workspaces(
src_token: str,
dst_token: str,
src_org: str,
dst_org: str,
src_hostname: str = "app.terraform.io",
dst_hostname: str = "app.terraform.io",
dst_project_id: str = "",
workspaces: str = "*",
) -> str:
"""Execute skybridge to copy workspaces from the source org to the
destination org and return the results immediately.
Pass workspaces as a comma-separated list of names (e.g. 'ws1,ws2,ws3') or leave as '*' to copy all workspaces."""
workspace_args = ["--workspaces", workspaces] if workspaces and workspaces != "*" else []
return run(["copy", "workspaces", *workspace_args])A few patterns matter in production:
- Co-locate the binary. We compile Skybridge for Linux (because Watsonx sandbox runs Linux) and place it in the same package directory.
- Docstrings are part of your API contract. Watsonx reads docstrings to decide when and how to call tools, so be explicit about required inputs, expected format, and side effects.
- Sandbox resource limits. Long-running operations and large state transfers can hit execution timeouts. We have seen this in high-volume state copy scenarios. We solved this by splitting operations into smaller batches and allowing the LLM to execute these through agent instructions.
Building and Deploying
Deployment is two steps. First, compile the binary for Linux (the Watsonx sandbox target).
GOOS=linux GOARCH=amd64 go build -ldflags="-s -w" -o watson_skill/skybridge_package/skybridge .
Then upload the tool to Watsonx:
orchestrate tools import -k python \
-f watson_skill/skybridge_package/skybridge_skill.py \
-r watson_skill/requirements.txt \
-p watson_skill/skybridge_packageThe flags break down as follows:
- -k python tells Watsonx this is a Python tool
- -f points to the skill file containing @tool functions
- -r points to your requirements file (ours just has ibm-watsonx-orchestrate)
- -p points to the package directory, including the compiled binary
After import completes, the tools are available to any configured agent. Watsonx picks up function signatures, docstrings, and parameter types automatically. You do not need to redesign your system to get value from AI agents. In many cases, a thin wrapper plus a well-defined interface is enough.
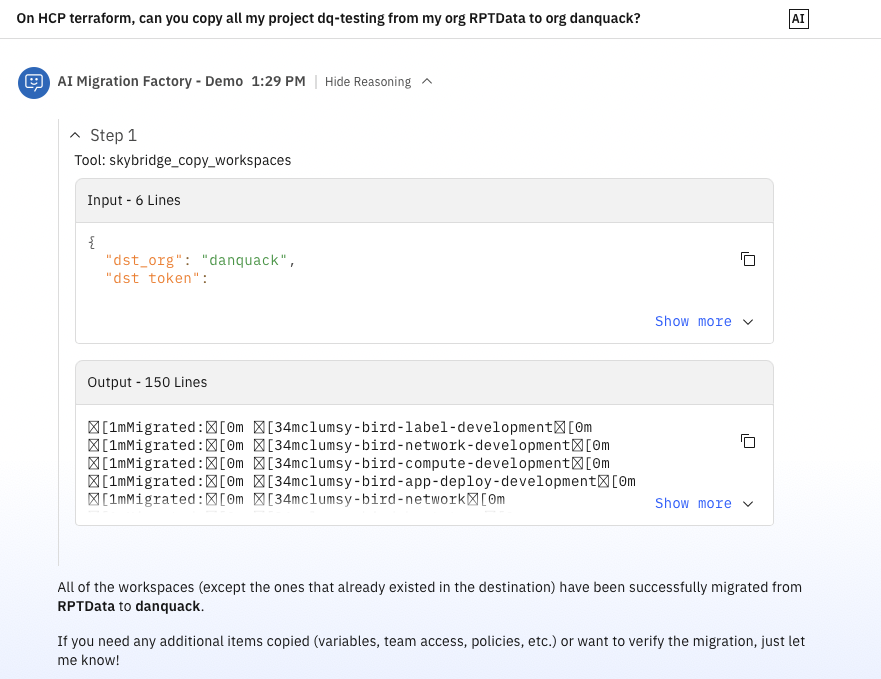
Using It
Once deployed, you can ask:
- “List all workspaces in the acme-prod org.”
- “Copy workspaces ws-api and ws-frontend from old-org to new-org.”
The agent chooses the right tool, asks for missing parameters, and runs the command.
Security Considerations
When you expose infrastructure operations through AI tools, guardrails matter:
- Use short-lived credentials and least-privilege scopes. For more secure connections, consider using orchestrate connections.
- Redact sensitive values from stdout/stderr before returning output
- Keep destructive operations explicit in docstrings (“This action modifies…”)
- Add approval gates for high-impact operations.

Eight months into leading River Point Technology’s AI Center of Excellence, the framework shaping our approach predates AI entirely — and that is precisely the point.
I joined River Point Technology last September as Director of Product and Business Solutions and was recently appointed the leader of our AI Center of Excellence, RPT Labs. The question I most often field from my fellow Product peers is some version of: “Where do we begin?”
The answer I have arrived at is not a tool, a vendor, or a model. It is a system.
Organizations that fail to incorporate AI into the core of how they operate will be outpaced — not in a decade, but in the present cycle. That is not a slogan; it is the operating reality of every services and product company. The firms that figure out how to be faster, more productive, and measurably smarter — both internally and in service of their clients — will outrun those still treating AI as a side initiative.
Yet, the failure I see most often is not inaction — it is the impulse to pursue everything at once.
The Wishlist Problem
Most AI Centers of Excellence I’ve witnessed or heard from firsthand are stuck in the same pattern. A backlog of ideas. A queue of vendor demonstrations. A leader who has lost the ability to say no because every prospect or idea feels as though it could be the one. Six months in, nothing has shipped. Twelve months in, the CoE is being reorganized.
This is not a talent problem. It is a portfolio management problem. AI generates an extraordinary volume of plausible ideas absent of a system to triage them. Every CoE becomes a scattered wishlist with no true process or direction.
VCT: A funnel, not a roadmap
At River Point Technology, we apply the same framework to AI that we apply to our core solutions business. We call it VCT — Value Creation Technology — developed by our founder, Jeff Eiben, well before AI became the question on every executive’s desk. That timing matters. VCT was built to discipline all portfolio decisions. We did not need to invent a new framework for AI. We only to apply the one we already trust.
VCT has three stages, and it operates as a product management funnel: Choose, Incubate, Scale.
Choose. Ideas arrive from every direction — our solution pillar leaders, our delivery engineers, our clients, the market. We require each idea to pass through the same evaluation before resources are assigned or funding is allocated. What value is created if this works? What does it cost to find out? What is the smallest version we can credibly test? What do we already possess that uniquely positions us to win? An idea that cannot answer these questions does not advance — regardless of who proposed it. Let’s also not forget AI isn’t necessarily the best answer to all problems. Not everything is a nail, so each hurdle/gap must be critically evaluated to determine if AI is truly the right answer – not just the new “easy button.”
Incubate. Ideas that survive Choose receive small, time-boxed investments with a hypothesis, budget, and deadline. The discipline at this stage is what separates serious CoEs from the rest: a willingness to kill an incubation early when the evidence is absent, and to invest more heavily when it is present. Most CoEs skip this stage and move directly to deployment. That is how many organizations end up with tools or so called “solutions” no one uses.
Scale. Only the ideas that survive Incubate — with demonstrated value and a clear path to repeatable economics — are scaled. Scale is where the meaningful capital goes, and where the wrong investment is most costly. VCT exists to ensure that capital is deployed only against bets that have already been validated.
Two streams, one funnel
Applying VCT to AI differs from applying it to a traditional offering in one important respect: we run it across two streams in parallel. Our solution pillar leaders are divided between internal AI initiatives and external AI offerings.
Internal is the operation of RPT itself — our back-office practices, delivery workflows, knowledge management, and sales operations. Faster, more productive, sharper about our own business.
External is how we serve our clients — the agents, integrations, and AI-augmented delivery patterns that appear in client engagements, alongside the platform, policy, and infrastructure work our delivery organization is bringing to market.
These are not separate strategies. They are the same funnel applied twice. The point I would press hardest with any CoE leader is this: an organization that has not made its own business faster and smarter with AI has no standing to advise its clients to do the same. Internal credibility precedes external credibility. Be your own client zero. The pillar split ensures investment in both, every quarter, with equal rigor.
Product management discipline, applied to a moving target
The deeper value of the VCT funnel — and this matters more in AI than in any category I have worked in — is that it imposes product management discipline on a market determined to behave like a technology fad. New models emerge weekly. New vendors arrive daily. The pull to chase is significant.
Product management has spent decades developing methods to evaluate ideas under uncertainty: funnel principles, hypothesis testing, kill criteria, stage gates. None of this is novel. What is novel is the conviction required to apply these methods to AI even as the noise outside argues for speed at any cost.
Eight months of clarity
What I have learned in my first eight months at River Point Technology is not that AI is difficult. It is that the organizations that will win at AI are the ones that resist the urge to treat AI as exceptional. Treat it as the most consequential portfolio decision your business is making — because it is — and apply the same disciplines you would apply to any other portfolio.
Choose. Incubate. Scale.
Without a funnel, you have a wishlist. And the market will not wait for you to sort it out.
If you are standing up an AI CoE — or refining one that has stalled — I welcome the conversation. DMs are open.

By Kevin Hospodar, Go-to-Market Leader, River Point Technology
IBM made an announcement this week that I think deserves more than a quick read and a LinkedIn like. They are expanding their enterprise security program for the AI era and joining Project Glasswing, an industry coalition built to protect critical software infrastructure. It is worth paying attention to. Not because it is surprising, but because it lines up exactly with what we have been telling clients for years. The organizations that win with AI are the ones that treat security and infrastructure as a strategy from the start, not something they bolt on later.
At River Point, we have worked with hundreds of enterprises on this exact problem. We are IBM’s longest-standing HashiCorp partner and have been recognized as Partner of the Year multiple years running. That is not a credential I drop to sound impressive. It means we have been in this space longer than almost anyone, through multiple platform shifts, and we have seen what works and what does not. That experience now shapes how we help clients navigate the broader IBM automation and security ecosystem.
IBM’s announcement leans on three pillars. I want to add some real context to each one, because awareness is not a plan.
1. You Cannot Secure Infrastructure You Have Not Standardized
IBM Concert is built to bring application, infrastructure, and network signals together into one operational view. The goal is to move organizations from watching dashboards to actually responding in a coordinated way. Good idea. But here is what I see when I walk into enterprise environments: the tooling is rarely the bottleneck.
The gap is almost always inconsistent infrastructure provisioning. Manual deployments. Undocumented resources. Configuration drift nobody is tracking. Those are the attack surfaces AI-powered attackers are now learning to find faster than your team can patch them.
Terraform, which is now part of the IBM automation platform, is how serious enterprises close that gap. When every resource is provisioned through code, reviewed through policy, and tracked through state, Concert actually has clean signal to work with. The visibility tools get smarter when the infrastructure underneath them is trustworthy.
Ask yourself: does your team have full visibility into what is running, where it lives, and who provisioned it? Or are you relying on security tools to find what better processes should have prevented in the first place?
2. Your Hybrid Cloud Footprint Is an Attack Surface. Treat It Like One.
IBM called out hybrid cloud environments across more than 175 countries as the landscape they are defending. That is the world most of our clients live in too. Multi-cloud, on-premises, edge deployments spread across regions and business units. The perimeter is gone. Identity is the boundary now.
This is where secrets management stops being a nice-to-have. HashiCorp Vault, now integrated into the IBM ecosystem, is the standard for dynamic secrets, certificate management, and zero-trust access at enterprise scale. When credentials are short-lived, automatically rotated, and tied to machine identity rather than someone’s memory or a config file, the damage from any breach shrinks considerably.
We have helped organizations move away from static, long-lived credentials scattered across pipelines and configuration files. The security improvement is real, but so is the operational relief. Developers and operators stop carrying the mental load of managing secrets manually. That matters more than people admit.
Here is the uncomfortable truth. AI-powered attacks are going after the credentials your team forgot about. The ones sitting in that old CI/CD pipeline. The ones in a config file from three years ago. Vault closes that door.
3. Running Open Source Without Enterprise Support Is a Risk Decision
IBM and Red Hat made a point of highlighting their commitment to maintaining enterprise-grade open source components, proactive patching, and rapid response when issues surface. That framing resonates with me because it mirrors exactly the conversation I have with clients about their HashiCorp deployments.
Moving from community-tier to enterprise is not about paying for something that used to be free. It is about buying certainty. Self-managed, community HashiCorp deployments carry real operational risk. Delayed patches. Unsupported configurations. No SLA when something breaks during a critical deployment at two in the morning. HCP, the HashiCorp Cloud Platform, is managed Vault and managed Terraform with the operational rigor that enterprise security teams actually need.
As IBM has brought HashiCorp into its automation platform strategy, there are real questions clients need to work through around existing deployments, licensing, and roadmap. River Point has been navigating HashiCorp transitions longer than any other partner in this ecosystem. That matters right now.
AI Is a Strategy. Not a Product.
IBM’s Project Glasswing framing gets this right. It is not about one vendor’s tool. It is about an entire ecosystem hardening itself against a new class of threat. I believe the same thing about AI more broadly.
The organizations approaching AI with a clear infrastructure, security, and governance foundation will keep pulling ahead. The ones treating it as a collection of point solutions will accumulate risk at the same rate they accumulate capability. I have watched that play out enough times to say it with confidence.
We built River Point’s practice around helping enterprises get in front of this, not respond to it after something breaks.
If IBM’s announcement started a conversation in your organization about where you actually stand, that conversation is worth continuing with us. We run executive briefings and working sessions built to assess your current state, identify what matters most, and build a path forward that is specific to your environment. No generic frameworks. Just direct counsel from a team that has done this across hundreds of organizations.
Reach out if you want to talk.
River Point Technology is IBM’s longest-standing and most successful HashiCorp partner, recognized as Partner of the Year across multiple consecutive years. We help enterprises design, implement, and operate secure infrastructure at scale across the IBM and HashiCorp portfolio.